Redis 实战:根据投票排序功能
前言
这个投票功能是参考自 《Redis 实战》 这本书的例子写的 Java 版本(原书是 Python 版的),虽然简单,但是作为 Redis 入门的第一个例子还是很不错的
需求分析
现在很多的网站,都有提供对文章进行点赞等投票性质的功能。
某种场景下,网站会根据文章的发布时间以及文章获得的投票数量来计算出一个评分,然后 根据这个评分来决定如何排序和展示文章。
而要构建一个这样的文章投票网站,我们首先要做的就是为这个网站设置一些数值和限制条件:如果一篇文章获得了超过 200 张投票,那么网站就认为这是一篇值得推荐的文章;假如网站每天有 1000 篇文章发布,而有 50 篇文章达到了这个要求,那么网站会把这 50 篇文章放到文章列表的前 100 位至少一天。
为了产生一个能够 随着时间流逝不断减少的评分,程序需要根据文章的发表时间和当前的时间来计算评分。
具体做法是: 将文章得到的投票数乘以一个常量,再加上文章的发布时间,得到的结果即为评分,然后根据这个评分进行排序。
例如:第一篇文章刚发布时是第一秒,而下一篇文章发布发布时是第二秒,那在都没有人点赞的情况下,第一篇文章的评分就低于第二篇文章
// zadd key score member
// now 当前时间,给个 432 初始评分
conn.zadd("score:", now + 432, article);
在这里我们将常量设为 432,因为一天为 86400 秒,投票的门槛数是 200,它们的比值即为 432,这样的话,文章每获得一张投票,评分即增加 432 分。
// zincrby 为集合 key 中成员 member 的 score 值加上增量,并调整位置,参数 score 可以是负数,表示递减
// 给评分排序文章表的有序集合加上增量
conn.zincrby("score:", 432, article);
我们除了计算文章的评分之外,还要使用 Redis 来有序的存储网站文章的各种信息。在这里,对于每篇文章,我们使用散列(hash)来存储它的标题,发表时间,作者,文章 url,以及获得的投票数等。

这里使用冒号作为分隔符本书使用冒号 : 来分隔名字的不同部分:比如图 1-8 里面的键名 article:92617 就使用了冒号来分隔单词 article 和文章的 ID 号 92617,以此来构建命名空间(namespace)。
使用
:作为分隔符只是个人喜好,不过大部分 Redis 用户也都是这么做的,另外还有一些常见的分隔符,如句号.斜线/,有些人甚至还会使用管道符号|无论使用哪个符号来做分隔符,都要保持分隔符的一致性。
另外,正对网站的所有文章,我们还需要两个有序集合 zset 来存储文章:
- 第一个有序集合,成员为文章 ID,分值为发布时间;
- 第二个有序集合,成员同样为文章 ID,但是分值为文章的评分。

这样的话,网站既可以按照发布时间的先后来展示文章,也可以按照文章的评分(受欢迎程度)来展示文章。
为了防止重复投票,我们还要为每篇文章记录一个已投票用户的名单。

所以,程序将为每篇文章创建一个集合,用来存储已投票用户的 ID,为了解决内存,我们还应当规定,当一篇文章发布超过一个月(或者你认为的合适的时间长度),用户将不能再对文章进行投票。同时文章评分将被固定,而记录文章已投票用户名单的集合也就可以删除了。
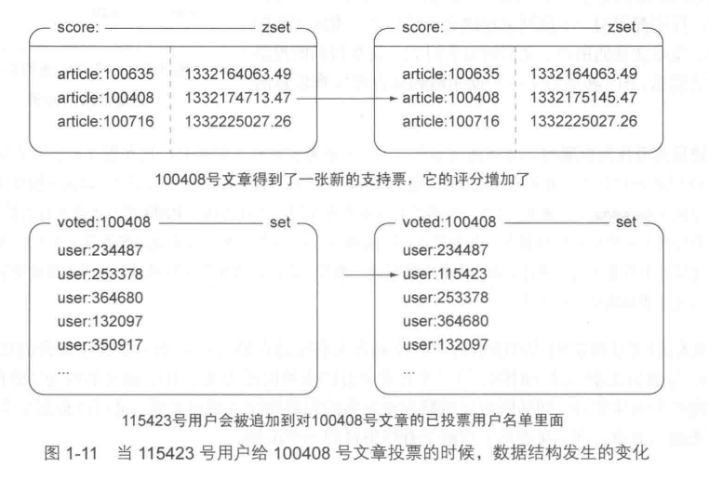
这里展示一下对于上面构建的结构实际投一个票(115423 号用户给 100408 号文章投票),数据是怎么样变化的
构建环境
因为主要是学习 Redis 的使用,所以这里就不整合到 SpringBoot 框架里面使用了
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
编写一个基本环境
public class VoteTest {
private static final int ONE_WEEK_IN_SECONDS = 7 * 86400; // 一个星期的时间(一天为 86400 秒)
private static final int VOTE_SCORE = 432; // 投票的评分
private static final int ARTICLES_PER_PAGE = 25; // 每页文章数
public static void main(String[] args) {
new VoteTest().run();
}
public void run() {
Jedis conn = new Jedis("10.1.1.161", 6379);
}
}
编写文章投票函数
/**
* 为文章投票
* @param conn Redis 连接
* @param user 投票的用户 ID
* @param article 文章 ID article:id 格式的(例如:article:92617)
*/
public void articleVote(Jedis conn, String user, String article) {
// 计算文章截止投票时间
long cutoff = (System.currentTimeMillis() / 1000) - ONE_WEEK_IN_SECONDS;
// 检查是否还可以对文章进行投票(虽然使用散列也可以获取文章的发布时间,
// 但是有序集合返回的文章发布时间为浮点数,可以不进行转换直接使用)
// zscore 方法:返回 key 处已排序集合的指定元素的分数
if (conn.zscore("time:", article) < cutoff){
return;
}
// 从 article:id 标识符里面取出文章
String articleId = article.substring(article.indexOf(':') + 1);
/*
sadd 用于操作 Set 类型数据
这个 sadd 返回值:如果添加了新元素返回 1,如果元素已经是集合的成员返回 0
这里把用户 id 插入这个文章的已投票用户列表里面
这个判断:如果用户是第一次为这篇文章投票,那么增加这篇文章的投票数量和评分
*/
if (conn.sadd("voted:" + articleId, user) == 1) {
// 为集合 key 中成员 member 的 score 值加上增量,并调整位置,参数 score 可以是负数,表示递减
// 给评分排序文章表的有序集合加上增量
conn.zincrby("score:", VOTE_SCORE, article);
// 方法表示为哈希表中域 field 的值递增常量 value;增量也可以为负数,相当于对给定域进行减法操作;
// 这里就是给文章信息表的 votes 字段加 1
conn.hincrBy(article, "votes", 1);
}
}
其实要正确的实现投票功能,这里的 sadd、zincrby 和 hincrBy 命令应该放在一个事务中执行,这里先暂时省略,后面再讲。
补充:
zscore 方法:返回 key 处已排序集合的指定元素的分数
zincrby 方法:为集合 key 中成员 member 的 score 值加上增量,并调整位置,参数 score 可以是负数,表示递减
hincrBy 方法:方法表示为哈希表中域 field 的值递增常量 value;增量也可以为负数,相当于对给定域进行减法操作;
发布并获取文章
发布文章需要先创建一个文章 ID,这项工作可以通过对一个计数器进行自增为 1 的操作来实现(执行 INCR 命令)。
接着程序需要使用 sadd 命令将文章发布者的 ID 添加到记录这篇文章已投票用户的集合里(避免自己给自己投票),并使用 expire 命令为这个集合设置一个过期时间,让 Redis 可以在到期后自动删除这个集合。
之后,系统还需要调用 hmset 命令来存储文章的相关详情信息,并执行两个 zadd 命令,将文章的初识评分和发布时间分别存到两个有序集合里。
/**
* 发布并获取文章
* @param conn Redis 连接
* @param user 发布文章的用户
* @param title 文章标题
* @param link 文章链接
* @return 返回 文章 ID article:id 格式的(例如:article:92617)
*/
public String postArticle(Jedis conn, String user, String title, String link) {
// 生成一个新的文章 ID(这里调用 incr 方法自增)
String articleId = String.valueOf(conn.incr("article:"));
String voted = "voted:" + articleId;
// 把自己添加进已投票用户列表,避免自己给自己投票
conn.sadd(voted, user);
// 设置这个已投票用户列表的过期时间
conn.expire(voted, ONE_WEEK_IN_SECONDS);
long now = System.currentTimeMillis() / 1000;
String article = "article:" + articleId;
// 将文章信息存储到 hash 里面
HashMap<String,String> articleData = new HashMap<>();
articleData.put("title", title);
articleData.put("link", link);
articleData.put("user", user);
articleData.put("now", String.valueOf(now));
articleData.put("votes", "1");
conn.hmset(article, articleData);
// 创建 根据评分排序文章的有序集合
conn.zadd("score:", now + VOTE_SCORE, article);
// 创建 根据发布时间排序文章的有序集合
conn.zadd("time:", now, article);
return articleId;
}
排序文章
那么接下来就要考虑怎样取出评分最高的文章或者最新发表的文章了。
为实现这两个功能,系统需要先使用 ZREVRANGE 命令取出多个文章 ID,然后再对每个 ID 执行一次 HGETALL 命令来取出文章的详情。这个方法既可以取出评分最高的文章,又可以用于取出最新发布的文章。
需要特别注意的是,有序集合会根据成员的分值从小到大去排列元素,所以要使用 ZREVRANGE 命令,以 “从大到小” 的排列顺序来取数据才是正确的做法。
/**
* 取得全部文章列表
*
* @param conn Redis 连接
* @param page 分页
* @return 文章集合
*/
public List<Map<String, String>> getArticles(Jedis conn, int page) {
return getArticles(conn, page, "score:");
}
/**
* 根据 key 取得文章集合
*
* @param conn Redis 连接
* @param page 分页
* @param order key(是按照分数排序 "score:",还是按照时间排序 "time:")
* @return 文章集合
*/
public List<Map<String, String>> getArticles(Jedis conn, int page, String order) {
// 设置获取文章的起始索引和结束索引
// ARTICLES_PER_PAGE 表示每页文章数
int start = (page - 1) * ARTICLES_PER_PAGE;
int end = start + ARTICLES_PER_PAGE - 1;
// 这个 order 参数就是这个排序集合的 key(这里传进来的 key 是 "score:")
Set<String> ids = conn.zrevrange(order, start, end);
List<Map<String, String>> articles = new ArrayList<>();
for (String id : ids) {
// 根据文章 ID 取得文章信息
Map<String, String> articleData = conn.hgetAll(id);
articleData.put("id", id);
articles.add(articleData);
}
return articles;
}
补充一个打印文章的方法:
/**
* 打印集合里面的文章
* @param articles 文章集合
*/
private void printArticles(List<Map<String, String>> articles) {
for (Map<String, String> article : articles) {
System.out.println(" id: " + article.get("id"));
for (Map.Entry<String, String> entry : article.entrySet()) {
if (entry.getKey().equals("id")) {
continue;
}
System.out.println(" " + entry.getKey() + ": " + entry.getValue());
}
}
}
文章分组
另外一个非常实用的功能是文章分类显示。这个功能可以让用户只看到与特定话题相关的文章。
群组功能有两个部分组成,一个部分负责记录文章属于哪个群组,另一个负责取出群组里的文章。为了记录各个群组都保存了哪些文章,网站需要为每个群组都创建一个集合,并将所有属于同一群组的文章 ID 都记录在群组里。
首先编写一个添加文章或移除文章的方法
/**
* 添加或者删除某篇文章到某个群组里面
*
* @param conn Redis 连接
* @param articleId 需要添加的文章 ID
* @param toAdd 需要添加到哪些群组
* @param toRemove 需要从哪些群组移除这篇文章
*/
public void addOrRemoveGroups(Jedis conn, String articleId, String[] toAdd, String[] toRemove) {
String article = "article:" + articleId;
if (toAdd != null) {
for (String group : toAdd) {
conn.sadd("group:" + group, article);
}
}
if (toRemove != null) {
for (String group : toRemove) {
conn.srem("group:" + group, article);
}
}
}
而为了能够根据评分对群组文章进行排序和分页,所有的文章也要按照分值大小有序的存到一个有序集合里。
Redis 的 ZINTERSTORE 命令可以接受多个集合和多个有序集合作为输入,然后找出他们的交集。并以几种不同的方式来合并(combine)成员的分值(所有的集合成员的分值默认为 1),最后以合并后的成员分值进行排序。
对于该投票网站来说,程序使用需要使用 ZINTERSTORE 命令选出相同成员中最大的那个分组来作为交集成员的分值
图 1-12 展示了对一个包含少量文章的群组集合和一一个包含 大量文章及评分的有序集合执行 ZINTERSTORE 命令的过程,注意观察那些同时出现在集合和有序集合里面的文章是怎样被添加到结果有序集合里面的。

这样,通过 对存储群组文章的集合 和 存储文章评分的有序集合 执行 ZINTERSTORE(并集)命令,我们可以 得到按照文章评分排序的文章群组;
而通过 对存储群组文章的集合 和 存储文章发表时间的有序集合 执行 ZINTERSTORE(并集)命令,我们可以 得到按照文章发表时间排序的文章群组。
注意:当群组较大时,执行 ZINTERSTORE 命令会较费时。为了减少 Redis 的工作量,可以考虑加上缓存(令这个命中的计算结果缓存 60 秒)。每次系统尝试去计算交集结果时,可以先去缓存中拿数据
同时可以重用上面的 getArticles 方法来分页并取得群组文章
/**
* 取得某个组里面的文章
*
* @param conn Redis 连接
* @param group 组的名称
* @param page 分页
* @return 某个组里面的文章
*/
public List<Map<String, String>> getGroupArticles(Jedis conn, String group, int page) {
return getGroupArticles(conn, group, page, "score:");
}
/**
* 根据 key 来取得某个组里面的文章
* @param conn Redis 连接
* @param group 组的名称
* @param page 分页
* @param order key(是按照分数排序 "score:",还是按照时间排序 "time:")
* @return 某个组里面的文章
*/
public List<Map<String, String>> getGroupArticles(Jedis conn, String group, int page, String order) {
// 为每个群组都创建一个键
String key = order + group;
// 因为 exists 返回值是 Boolean 类型,可能为 null 所以这里需要使用 Boolean.FALSE.equals 来判断
// 检查是否有已缓存的排序结果,如果没有的话,就进行排序
if (Boolean.FALSE.equals(conn.exists(key))) {
// 这个 ZParams 就是专门用来构建参数的(建造者方法)
ZParams params = new ZParams().aggregate(ZParams.Aggregate.MAX);
// zinterstore 用来求并集
conn.zinterstore(key, params, "group:" + group, order);
// 让 Redis 在 60秒之后自动删除这个有序集合
conn.expire(key, 60);
}
// 调用上面那个写好的获取文章的方法来进行分页并获取文章数据
return getArticles(conn, page, key);
}
补充:求并集的方法
zunionstore 方法用于计算一个或多个集合的并集,并将并集结果储存到 dstkey 集合中,默认情况下,结果集中某个成员的 score 值是所有给定集下该成员 score 的值之和(如果并集的是一个排序数组和一个非排序数组,那非排序数组的 score 值默认为 1)。
当然有一个选项 AGGREGATE 可以设置指定 score 的模式,也就是通过参数 ZParams 的枚举对象 Aggregate 来指定具体的模式:
SUM,就是计算所有的和; MIN,取最小值,MAX,取最大值;
示例:
ZParams params = new ZParams().aggregate(ZParams.Aggregate.MAX);
// zinterstore 用来求并集
conn.zinterstore(key, params, "group:" + group, order);
另外,还有一个选项 WEIGHTS 可以为有序集合指定一个乘法因子(multiplication factor),每个给定有序集的所有成员的 score 值都会乘以该有序集的因子。
如果没有指定 WEIGHTS 选项,乘法因子默认设置为 1 ,其中该选项通过 ZParams 的 weightsByDouble 方法来指定。
public Long zunionstore(final String dstkey, final String... sets)
public Long zunionstore(final String dstkey, final ZParams params, final String... sets)
而另一个方法 zinterstore 则是用于计算一个和多个集合的交集,并将结果保存到 dstkey 集合中,其他参数则和 zunionstore 方法是一致的:
public Long zinterstore(final String dstkey, final String... sets)
public Long zinterstore(final String dstkey, final ZParams params, final String... sets)
测试投票排序
现在对上面编写的一些方法进行测试:
public static void main(String[] args) {
new VoteTest().run();
}
public void run() {
Jedis conn = new Jedis("10.1.1.161", 6379);
conn.select(15);
// 首先发布几篇文章
String articleId = postArticle(conn, "username", "A title", "http://www.google.com");
String articleId02 = postArticle(conn, "username02", "A title02", "http://www.google.com");
String articleId03 = postArticle(conn, "username02", "A title02", "http://www.google.com");
String articleId04 = postArticle(conn, "username02", "A title02", "http://www.google.com");
System.out.println("发送的新文章 ID: " + articleId + "、" + articleId02 + "、" + articleId03 + "、" + articleId04);
System.out.println("打印第一篇 Hash 表里面的内容:");
// 打印第一篇的内容
Map<String, String> articleData = conn.hgetAll("article:" + articleId);
for (Map.Entry<String, String> entry : articleData.entrySet()) {
System.out.println(" " + entry.getKey() + ": " + entry.getValue());
}
System.out.println();
// 给文章投票
articleVote(conn, "other_user", "article:" + articleId);
articleVote(conn, "other_user02", "article:" + articleId);
articleVote(conn, "other_user03", "article:" + articleId02);
articleVote(conn, "other_user04", "article:" + articleId02);
articleVote(conn, "other_user05", "article:" + articleId02);
String votes = conn.hget("article:" + articleId02, "votes");
System.out.println("检查第二篇文章,现在它有了选票: " + votes);
assert Integer.parseInt(votes) > 1;
System.out.println("目前得分最高的文章是:");
List<Map<String, String>> articles = getArticles(conn, 1);
printArticles(articles);
assert articles.size() >= 1;
// 把文章丢进分组里面
addOrRemoveGroups(conn, articleId, new String[]{"new-group"}, new String[]{});
addOrRemoveGroups(conn, articleId02, new String[]{"new-group02"}, new String[]{});
addOrRemoveGroups(conn, articleId04, new String[]{"new-group"}, new String[]{});
System.out.println("我们将文章添加到一个新组,这个分组的文章包括: ");
articles = getGroupArticles(conn, "new-group", 1);
printArticles(articles);
assert articles.size() >= 1;
}
输出:
发送的新文章 ID: 1、2、3、4
打印第一篇 Hash 表里面的内容:
link: http://www.google.com
votes: 1
title: A title
user: username
now: 1626851058
检查第二篇文章,现在它有了选票: 4
目前得分最高的文章是:
id: article:2
link: http://www.google.com
votes: 4
title: A title02
user: username02
now: 1626851058
id: article:1
link: http://www.google.com
votes: 3
title: A title
user: username
now: 1626851058
id: article:4
link: http://www.google.com
votes: 1
title: A title02
user: username02
now: 1626851058
id: article:3
link: http://www.google.com
votes: 1
title: A title02
user: username02
now: 1626851058
我们将文章添加到一个新组,这个分组的文章包括:
id: article:1
link: http://www.google.com
votes: 3
title: A title
user: username
now: 1626851058
id: article:4
link: http://www.google.com
votes: 1
title: A title02
user: username02
now: 1626851058
检查 Redis 数据库